Yesterday, OpenAI announced their new o3 model. One of the big claims was reaching the very high performance of 76% on ARC-AGI-SemiPub,and as high as 91% on the public set (after spending $1.6 million dollars on compute just to run inference on this one benchmark - about $3,000 per task, in addition to fine-tuning costs).1
Since this post, I’ve published an article deep-diving the advances that o3 made, its mistakes, and how ARC may be a misleading metric for LLM reasoning:
So, of the 400 tasks in ARC-AGI-Pub, here are the 34 tasks that o3 was unable to solve, along with the incorrect guesses it made:
I’ve seen this one on Twitter a bunch, where people are surprised o3 can’t solve it (without seeing the attempts). I actually think the examples are underspecified and that o3’s first solution is correct.
This task is the only example in the whole dataset where the model is unable to output a grid at all - adding erroneous extra squares on some rows. You see this sort of thing a lot with smaller LLMs on ARC.
This one is deceptively challenging. A person might also produce the first attempt initially, by analogy from Example 5 (without thinking through the other examples).
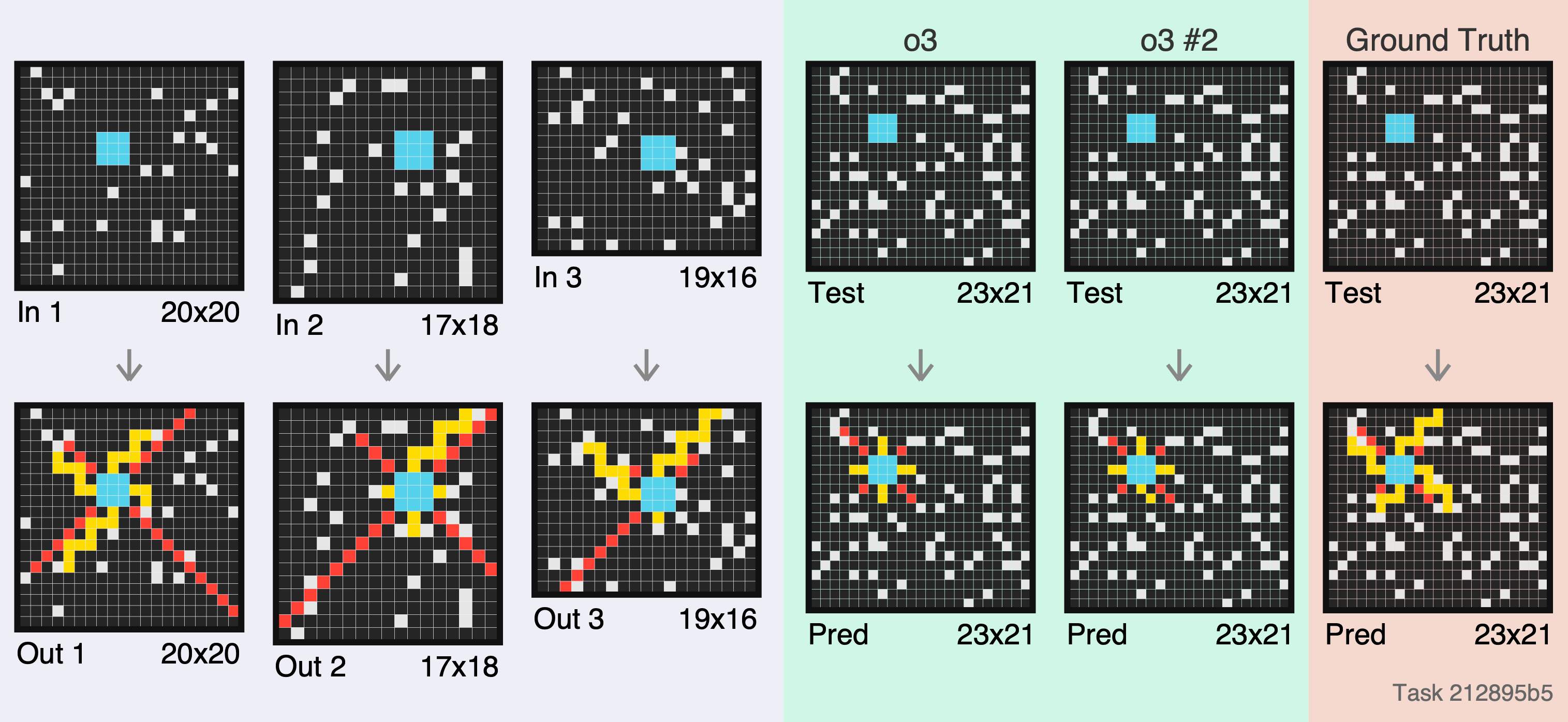
Another one with difficult spatialreasoning, instead of requiring complex changes to the grid.
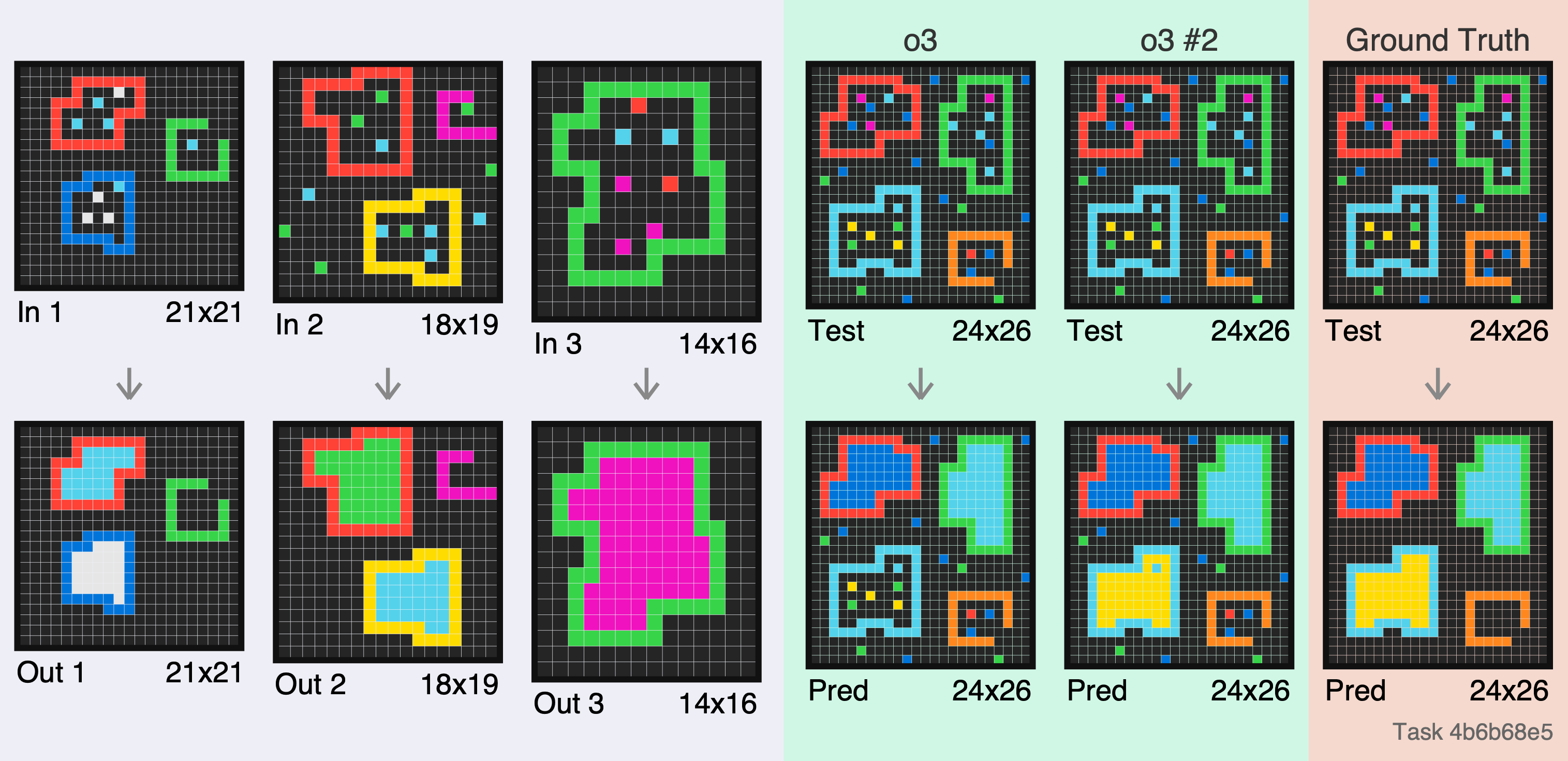
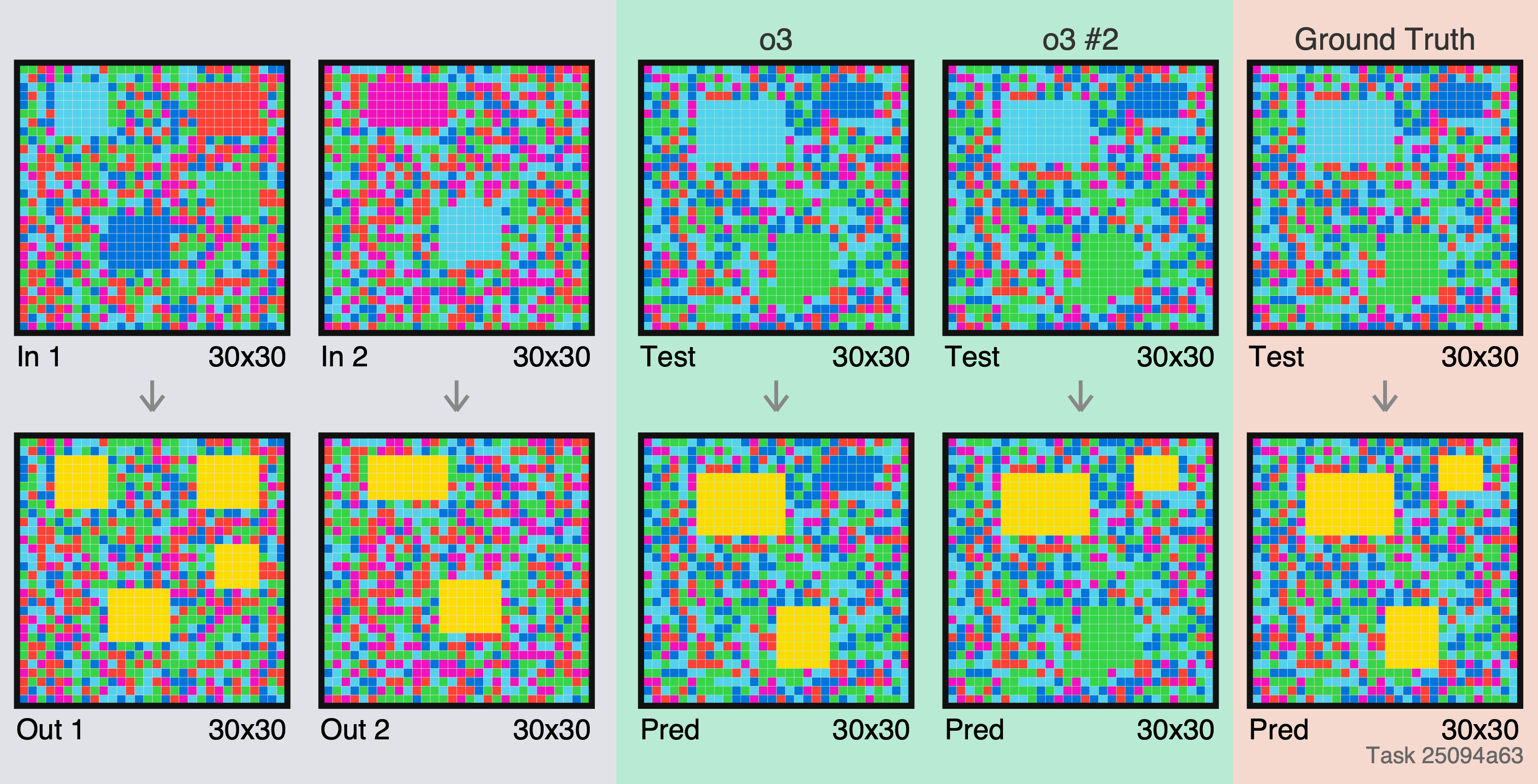
A valiant effort to perform inpainting - but a couple mistakes. In the 2nd attempt, o3 just generates several strips of constant output (obviously incorrect), despite all the reasoning tokens. If I was anthropomorphising, i’d say it gave up!
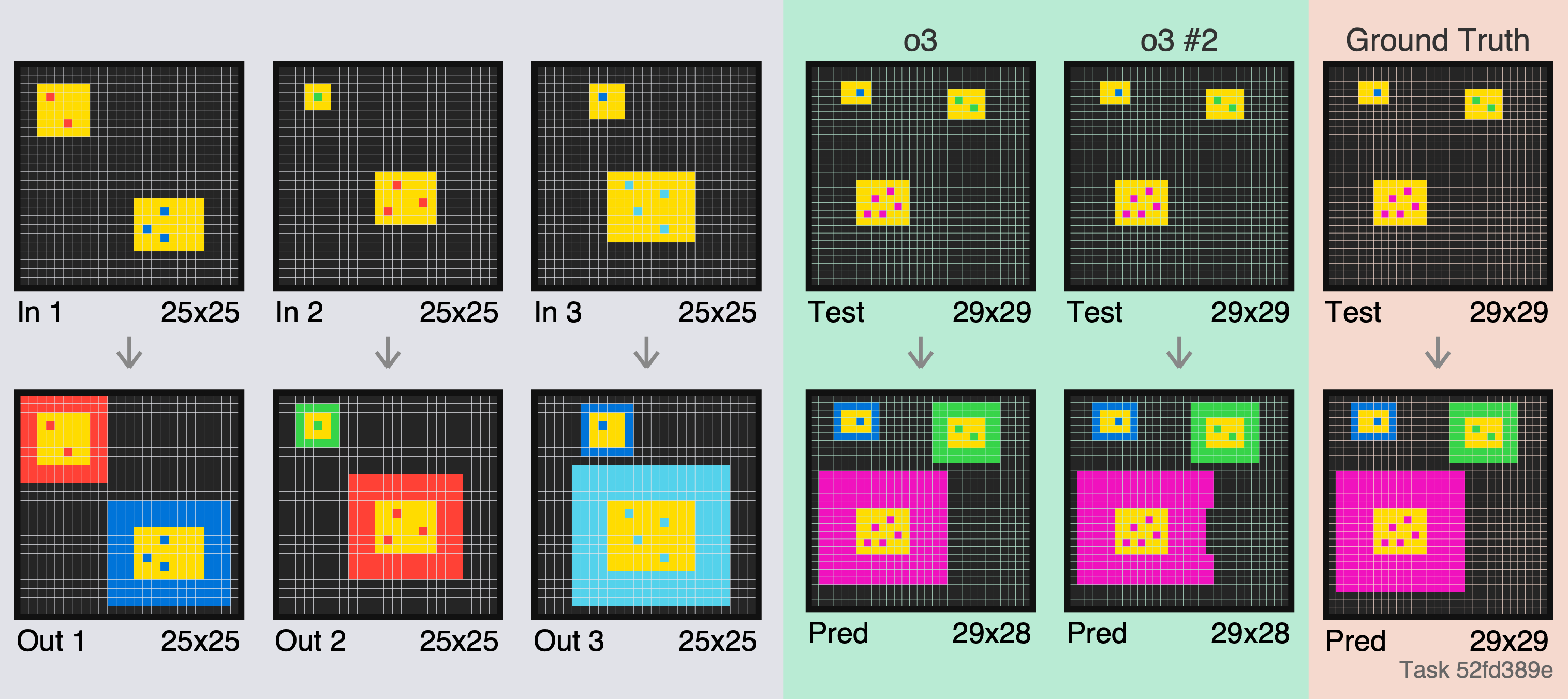
The test example is much larger than the training examples, which is interesting here.
o3 outputted a single black pixel? Maybe the poorest showing here, and very hard to explain. I think it’s possible o3 gave up again here - although it’s unclear if OpenAI told the model it was wrong the first time.
The rows are individually correct, but misaligned on the broader grid.
o3 dropped a row in both instances (and some columns).
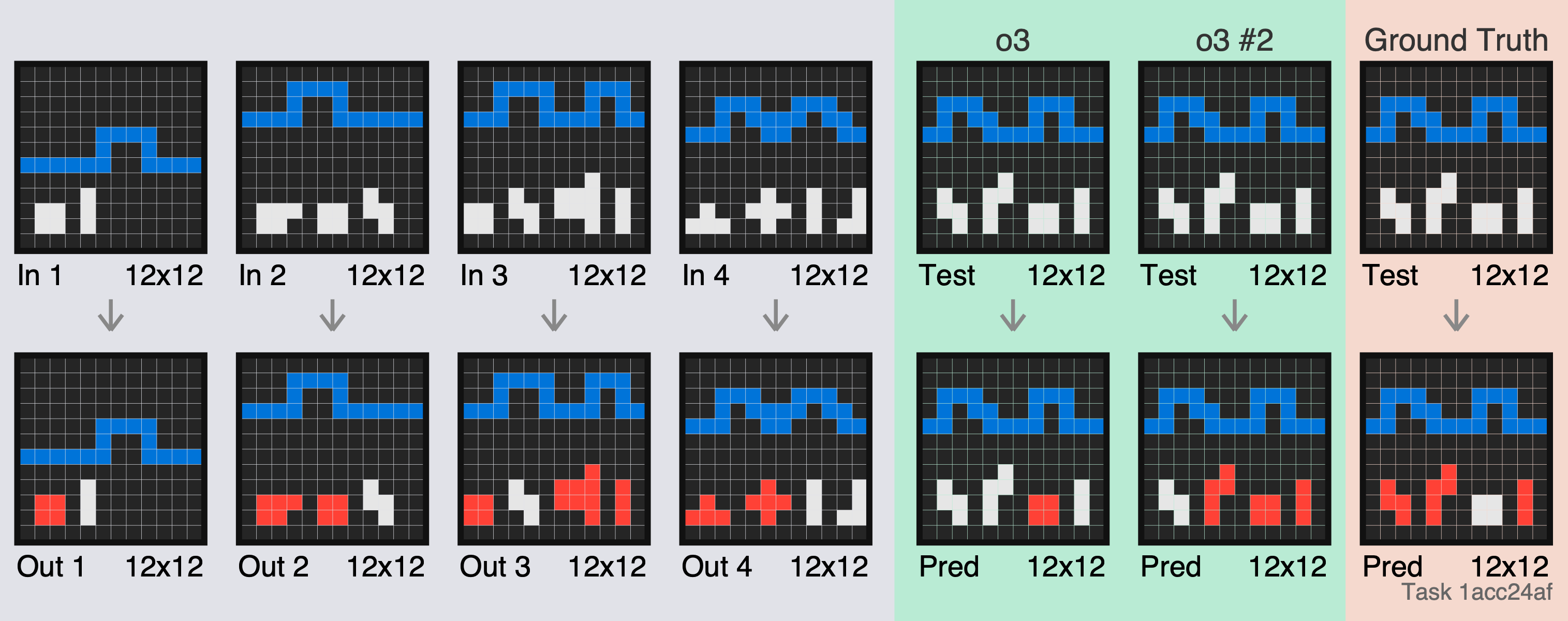
o3 is totally unable to perform tetris here - we saw the same thing earlier in [1acc24af].
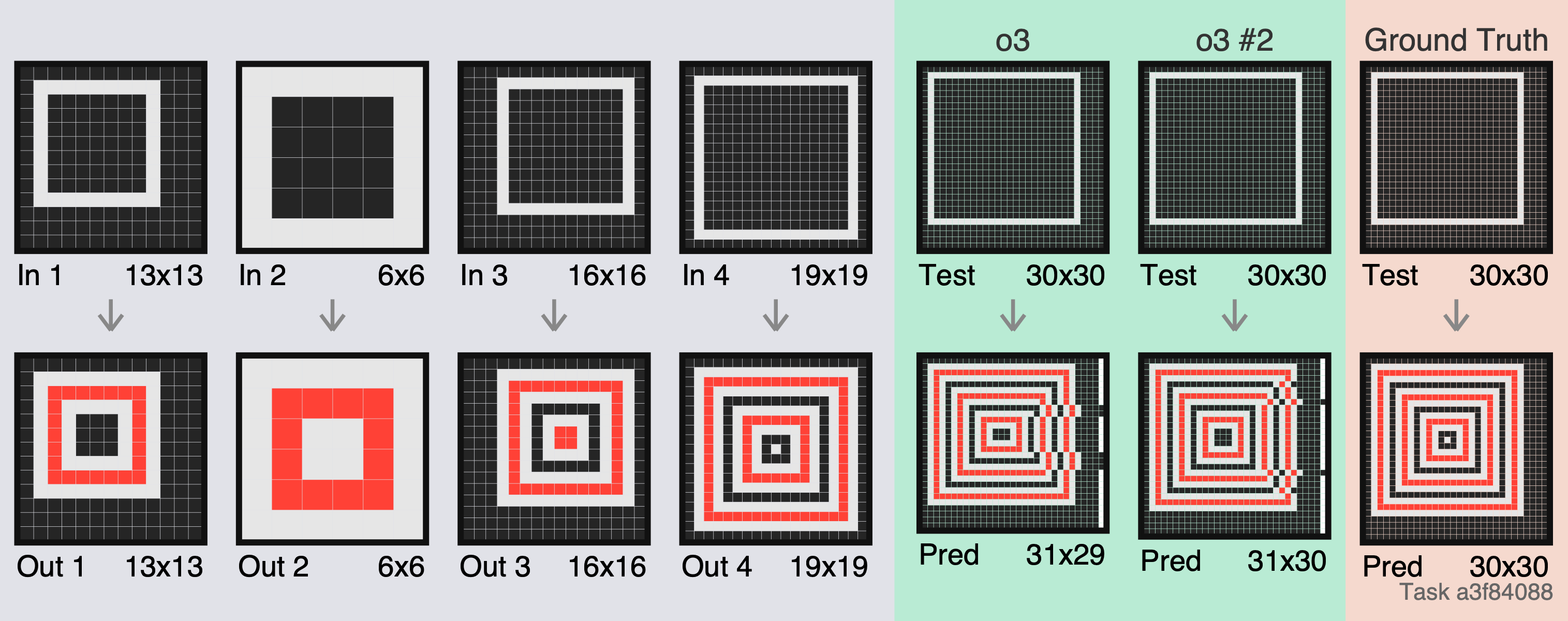
Both times here, o3 dropped a line from the prediction. Looks like it struggles to keep track of how many (identically repeated) lines it has left to output.
You can check out the data for yourself here, with visualisations made with my arckit library. I’d love to hear your thoughts!
As an interesting aside, here’s an example of how the first generation of LLMs did on ARC (from our previous work, Neural Networks for Abstraction & Reasoning). As model scale improves, we see better and better abilities to avoid mistakes, even if some of the reasoning is there from the beginning.
The ARC organisers impose a inference limit of $10,000 on the Semi-public set, so that explains most of the lower score. It’s worth noting that neither of these sets represent the actual ARC prize, which requires much more restricted compute.































You missed one, which I also missed initially https://o3-failed-arc-agi.vercel.app/
Failed task 8b28cd80
Here, the task had 2 tests, not just 1
Out of 400 task, 19 task had 2 test
Thanks for doing this -- very useful.